Memory Swapping Detection and Mitigation in the Pepperdata Supervisor (Cloud)
Swapping is a memory management technique that computer operating systems (OSes) use to ensure that RAM is maximally used on processes that need it. During swapping, the OS moves processes between virtual memory on disk and physical RAM. Swapping is a normal, expected part of operation, but it can be a problem when there are too many processes scheduled to run at once.
When the OS spends too much time loading and unloading pages from disk onto memory—referred to as thrashing—the computer’s performance degrades, at best, and at worst the computer can become inoperable. In a distributed computing environment such as Hadoop, if even just a single machine slows down due to excessive swapping, it can negatively affect jobs across the entire cluster. Therefore, it’s imperative that cluster operators be able to quickly identify hosts that are excessively swapping, and take mitigating actions such as killing jobs to reduce both swapping and overall load on the host.
Automatic Swap Detection and Response
The Pepperdata Supervisor employs a machine learning (ML) algorithm that continuously monitors metrics such as pages of memory being swapped in and out of physical RAM, and detects when there is excessive swapping on any host in the cluster.
The Swap State metric (metric code-name, n_sdss) keeps track of the level of swapping on each host.
In This Section
- Swap State Metric Values
- Interpret the Charts: Automatic Swap Detection and Response
- Disable Automatic Swap Detection and Response
Swap State Metric Values
The table describes the values the Swap State metric can take.
| Swap State | Host’s Swapping Conditions | Pepperdata Supervisor Response |
|---|---|---|
| 0 | Normal | No action needed. |
| 1 | Warning: The number of pages being swapped has crossed a threshold that can trip the host to extreme swapping if more jobs are added. | If Pepperdata Capacity Optimizer is enabled on the host, Capacity Optimizer stops adding capacity so that the Hadoop scheduler does not add jobs on the host. |
| 2 | Extreme: The number of pages being swapped has crossed a critical threshold, and load must be reduced to avoid thrashing. | To relieve pressure on the host, Pepperdata Supervisor selectively kills tasks on the host. Newly launched YARN containers are killed first, which means that MapReduce is targeted before long-running YARN containers such as Apache Spark and Apache Tez. Application Masters and HBase daemons are never killed. |
Interpret the Charts: Automatic Swap Detection and Response
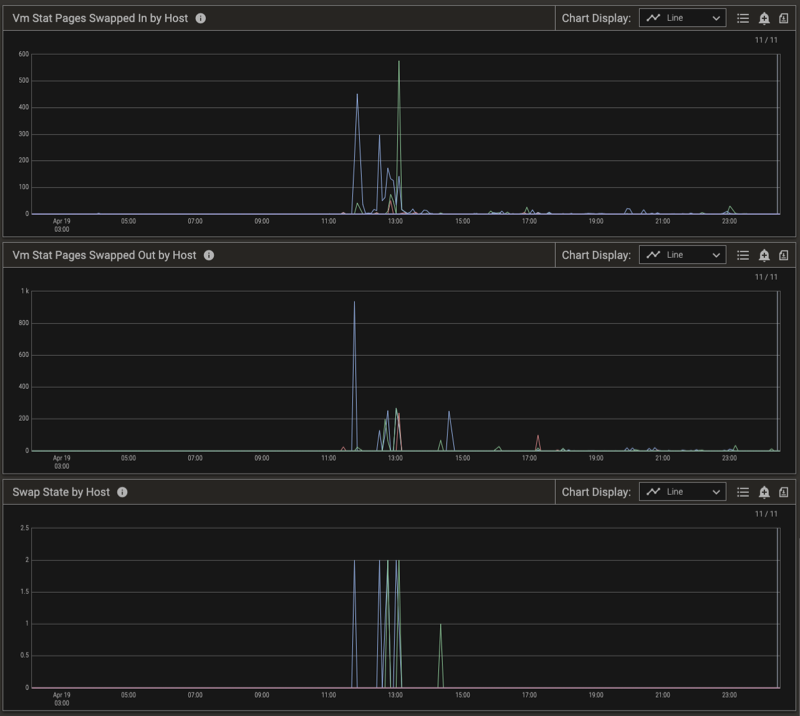
To further explain how Pepperdata performs automatic detection and response, let’s examine a single host on a medium-size production cluster (~100 hosts) running thousands of tasks. Pepperdata Supervisor monitors the Swap State of each host in the cluster, evaluating the number of pages swapped in and out (see the Vm Stat Pages Swapped in by Host and Vm Stat Pages Swapped Out by Host charts, below), and takes action on a per-host basis in near real time to prevent thrashing.
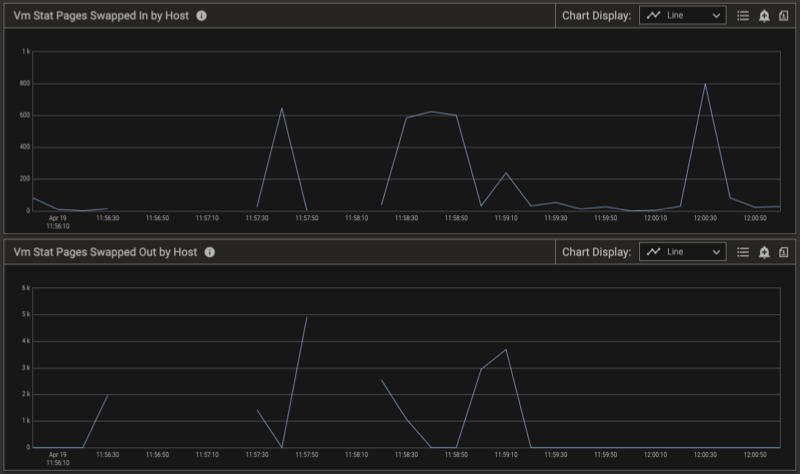
The Swap State changes from 0 (Normal) to 2 (Extreme) when the relative number of pages swapped out and in indicates extreme swapping on this host. To prevent thrashing on the host, Pepperdata Supervisor steps in, and in conjunction with YARN starts killing tasks to return the swapping to a normal level. This is shown in the charts by the Swap State returning to 0. You can confirm the results by observing the free memory available on the host. (See the Swap State by Host chart, below.)
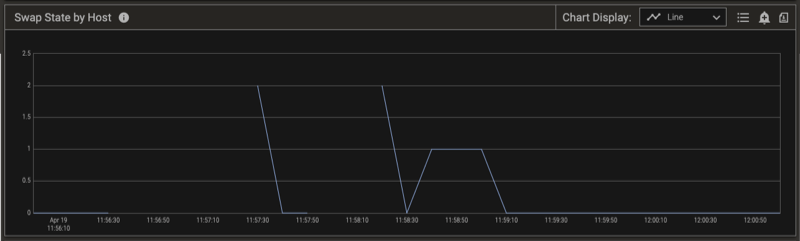
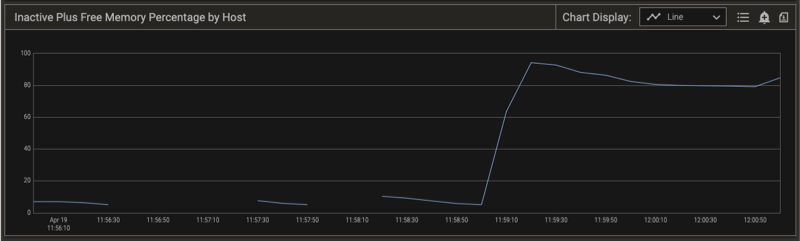
Notice the time stamps for the Swap State by Host chart (above) and the total Inactive Plus Free Memory Percent by Host chart (below). When the Swap State indicates extreme swapping, the free memory on the host drops to zero (0). As the Pepperdata Supervisor kills tasks to reduce the pressure on the host, the available memory increases and the Swap State on the host returns to zero (0), indicating the return to the desired Normal condition. Note that the only tasks that Pepperdata Supervisor kills are Mappers, Reducers, and YARN containers.
Disable Automatic Swap Detection and Response
Procedure
-
In your cloud environment (such as GDP or AWS), add the
pepperdata.supervisor.allocation.swap.response.enabledproperty (with a value offalse) to the Pepperdata configuration..-
From the environment’s cluster configuration folder (in the cloud), download the Pepperdata site file,
/etc/pepperdata/pepperdata-site.xml, to a location where you can edit it. -
Open the file for editing, and add the required property.
<property> <name>pepperdata.supervisor.allocation.swap.response.enabled</name> <value>false</value> </property>Malformed XML files can cause operational errors that can be difficult to debug. To prevent such errors, we recommend that you use a linter, such asxmllint, after you edit any .xml configuration file. -
Save your changes and close the file.
-
Upload the revised file to overwrite the original
pepperdata-site.xmlfile.
If there are no already-running hosts with Pepperdata, you are done with this procedure. Do not perform the remaining steps. -
-
Open a command shell (terminal session) and log in to any already-running host as a user with
sudoprivileges.Important: You can begin with any host on which Pepperdata is running, but be sure to repeat the login (this step), copying the bootstrap file (next step), and loading the revised Pepperdata configuration (the following step) on every already-running host. -
From the command line, copy the Pepperdata bootstrap script that you extracted from the Pepperdata package from its local location to any location; in this procedure’s steps, we’ve copied it to
/tmp.-
For Amazon EMR clusters:
aws s3 cp s3://<pd-bootstrap-script-from-install-packages> /tmp/bootstrap -
For Google Dataproc clusters:
sudo gsutil cp gs://<pd-bootstrap-script-from-install-packages> /tmp/bootstrap
-
-
Load the revised configuration by running the Pepperdata bootstrap script.
-
For EMR clusters:
-
You can use the --long-options form of the
--bucket,--upload-realm, and--is-runningarguments as shown or their -short-option equivalents,-b,-u, and-r. -
The
--is-running(-r) option is required for bootstrapping an already-running host prior to Supervisor version 7.0.13. -
Optionally, you can specify a proxy server for the AWS Command Line Interface (CLI) and Pepperdata-enabled cluster hosts.
Include the
--proxy-address(or--emr-proxy-addressfor Supervisor version 8.0.24 or later) argument when running the Pepperdata bootstrap script, specifying its value as a fully-qualified host address that useshttpsprotocol. -
If you’re using a non-default EMR API endpoint (by using the
--endpoint-urlargument), include the--emr-api-endpointargument when running the Pepperdata bootstrap script. Its value must be a fully-qualified host address. (It can usehttporhttpsprotocol.) -
If you are using a script from an earlier Supervisor version that has the
--clusteror-carguments instead of the--upload-realmor-uarguments (which were introduced in Supervisor v6.5), respectively, you can continue using the script and its old arguments. They are backward compatible. -
Optionally, you can override the default exponential backoff and jitter retry logic for the
describe-clustercommand that the Pepperdata bootstrapping uses to retrieve the cluster’s metadata.Specify either or both of the following options in the bootstrap’s Optional arguments. Be sure to substitute your values for the
<my-retries>and<my-timeout>placeholders that are shown in the command.-
max-retry-attempts—(default=10) Maximum number of retry attempts to make after the initialdescribe-clustercall. -
max-timeout—(default=60) Maximum number of seconds to wait before the next retry call todescribe-cluster. The actual wait time for a given retry is assigned as a random number, 1–calculated timeout (inclusive), which introduces the desired jitter.
-
-
# For Supervisor versions before 7.0.13: sudo bash /tmp/bootstrap --bucket <bucket-name> --upload-realm <realm-name> --is-running [--proxy-address <proxy-url:proxy-port>] [--emr-api-endpoint <endpoint-url:endpoint-port>] [--max-retry-attempts <my-retries>] [--max-timeout <my-timeout>] # For Supervisor versions 7.0.13 to 8.0.23: sudo bash /tmp/bootstrap --bucket <bucket-name> --upload-realm <realm-name> [--proxy-address <proxy-url:proxy-port>] [--emr-api-endpoint <endpoint-url:endpoint-port>] [--max-retry-attempts <my-retries>] [--max-timeout <my-timeout>] # For Supervisor versions 8.0.24 and later: sudo bash /tmp/bootstrap --bucket <bucket-name> --upload-realm <realm-name> [--emr-proxy-address <proxy-url:proxy-port>] [--emr-api-endpoint <endpoint-url:endpoint-port>] [--max-retry-attempts <my-retries>] [--max-timeout <my-timeout>]-
For Dataproc clusters:
sudo bash /tmp/bootstrap <bucket-name> <realm-name>
The script finishes with a
Pepperdata installation succeededmessage. -
-
Repeat steps 2–4 on every already-running host in your cluster.
To re-enable the controls, remove the property or change its value to true in the Pepperdata configuration, and for every already-running host, log in and load the revised Pepperdata configuration.
Verifying Swap Detection Behavior
You can verify that swap detection and response are working as expected by viewing the applicable charts.
Procedure
-
In the left-nav menu, select Charts.
-
In the filter bar, click Metrics.
-
In the search box, clear any previously selected metrics, and enter the search term, “swap” (without the quotation marks), and select the following metrics from the Host > Memory > Memory information group:
swap statevm stat pages swapped invm stat pages swapped out
-
In the search box, replace the “swap” string with “inactive”, and select either or both of the following metrics from the Host > Memory > Memory information group:
inactive plus free memoryinactive plus free memory percentage
-
Click Apply.
-
(Optional) From the filter bar, change the time range, select breakdowns and filters, and/or change advanced options, and click Apply.
If you did not change the series breakdowns from the default Summary value, the Pepperdata dashboard shows summaries for the resulting charts. To focus on the specific hosts that experienced excessive swapping in the time range that you selected, use the Legend to filter the results.
The charts below show a cluster that experienced some swapping, as well as the corresponding metrics.